-
ElasticSearch 정리공부방 2023. 12. 25. 22:42
ElasticSearch 란?

1. 검색엔진
엘라스틱서치는 이름 그대로 검색 엔진입니다. 다른 RDBMS 또는 NoSQL에 비해 매우 강력한 검색 기능을 지원합니다.
역색인을 사용하여 검색 속도가 굉장히 빠르고 다양한 애널라이저를 조합하여 여러 비즈니스 요구사항에 맞는 색인을 구성할 수 있습니다.
2. 분산처리
엘라스틱서치는 분산 처리를 고려하여 설계되었습니다. 데이터를 여러 노드에 분산 저장하고 이 때문에 수평적 확장성이 좋고 고가용성을 제공할 수 있습니다.
3. JSON 기반
엘라스틱서치는 문서를 JSON 형태로 저장하고 관리합니다. 요청 역시 JSON 기반으로 받기 때문에 환경에 구애받지 않고 HTTP를 통해 쉽게 이용할 수 있습니다.
4. 트랜잭션이 지원되지 않음
엘라스틱서치는 RDBMS와 다르게 트랜잭션이 지원되지 않습니다. 서비스와 데이터 설계 시 이 점을 고려하여야 합니다.
5. 다양한 플러그인을 통한 기능 확장
엘라스틱서치는 다양한 플러그인을 사용해 기능을 확장하거나 변경할 수 있습니다. 여러 플러그인을 통해 비즈니스 요구사항에 따라 다양하게 커스터마이즈 할 수 있습니다.
ElasticSearch 동작 구조
구조 개괄
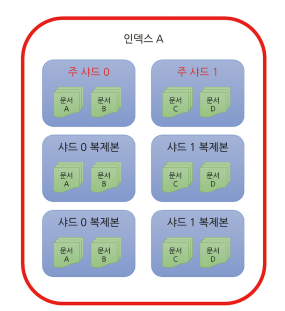
인덱스와 샤드 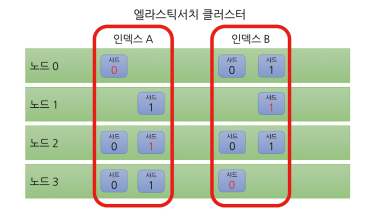
엘라스틱서치 클러스터 ● 인덱스
문서를 모아놓은 기본 단위. 클라이언트는 인덱스 단위로 엘라스틱서치에 검색을 요청하게 됩니다.
● 샤드
인덱스는 그 내용을 여러 샤드에 분산하여 저장합니다. 엘라스틱 서치는 고가용성을 위해 샤드의 내용을 따로 복제하여 관리합니다.
● 문서
엘라스틱서치가 저장하고 색인을 생성하는 JSON 문서를 뜻합니다.
● 노드
엘라스틱서치 프로세스 하나가 노드 하나를 구성한다. 엘라스틱서치는 고가용성을 위해 같은 종류의 샤드를 같은 노드에 배치하지 않는다.
● 클러스터
여러 엘라스틱서치 노드 여러 개가 모여 하나의 클러스터를 구성합니다.
노드의 역할
노드에는 역할이라는 개념이 있습니다. 클러스터 구성을 위해서는 반드시 노드의 역할을 지정해 주어야 합니다. 각 노드는 여러 역할을 수행할 수도 있습니다. 아래의 예시 외에도 다양한 노드들이 존재합니다.
● 마스터 후보 노드
노드에 마스터 역할을 주면 마스터 후보 노드가 됩니다. 마스터 후보 노드중 선거를 통해 마스터 노드가 결정됩니다. 마스터 노드는 클러스터 관리 역할을 하게 됩니다. 인덱스 생성, 삭제, 샤드 배치 등 중요한 역할을 수행합니다.
● 데이터 노드
실제로 데이터를 들고있는 노드입니다. CRUD, 검색 등 데이터와 관련된 일을 처리합니다.
● 인제스트 노드
데이터가 색인되기 전에 전처리를 수행해주는 파이프라인 노드입니다.
● 조정 노드
클라이언트의 요청을 받아 다른 노드에 요청을 분배하고 최종 응답을 돌려주는 노드입니다. 기본적으로 모든 노드가 조정 역할을 수행합니다. 다른 역할을 수행하지 않고 조정 역할만 하는 노드는 조정 전용 노드라고 합니다.
● 데이터 티어 노드
데이터 노드를 용도 및 성능별로 hot-warm-cold-frozen 티어로 구분하여 저장하는 노드입니다.
동작 구조와 루씬

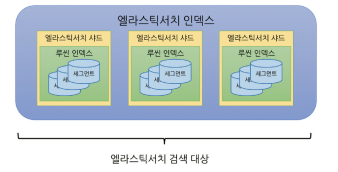
● 루씬 flush
엘라스틱서치는 아파치 루씬을 코어 라이브러리로 사용합니다. 문서 색인 요청이 들어오면 루씬은 문서를 분석해서 인메모리 버퍼에 역색인을 생성합니다. 문서 색인, 업데이트, 삭제 등의 작업 내용들도 인메모리 버퍼에 저장하다가 주기적으로 디스크에 flush 합니다.
● ElasticSearch refresh
루씬은 색인한 정보를 파일로 저장하기 때문에 루씬에서 검색하려면 파일을 열어야 합니다. 루씬은 파일을 연 시점에 색인된 파일들만 문서로 검색할 수 있는데. 이 후 색인에 변경사항이 있다면 새로 파일을 열어야 합니다. 이렇게 새로 파일을 여는 과정을 엘라스틱서치에서는 refresh 라고 합니다. 이 단계까지 온 데이터가 검색 대상이 됩니다.
● 루씬 commit
루씬 flush는 데이터를 넘겨주는 것까지만 보장할 뿐 디스크에 파일이 기록되는 것까지 보장하지는 않습니다. 따라서 루씬은 fsync 시스템 콜을 통해 주기적으로 디스크에 기록된 내용의 싱크를 맞추는 작업을 수행하고 이를 루씬 commit 이라 합니다.
● ElasticSearch flush
엘라스틱서치 flush 작업은 내부적으로 루씬 commit을 진행합니다. 엘라스틱서치 refresh와 마찬가지로 명시적으로 작업 수행을 지시할 수 있다. 또 새로운 translog를 만들어 translog 크기를 적절히 유지 시켜준다.
● 세그먼트
디스크에 기록된 파일들이 모이면 세그먼트가 됩니다. 이 세그먼트가 루씬의 검색 대상입니다. 세그먼트는 불변인 데이터로 기존 문서에 업데이트가 발생할 경우 삭제 플래그를 표시하고 새 세그먼트를 생성합니다.
세그먼트의 개수를 무작정 늘릴수는 없기에 중간중간 세그먼트 병합을 수행합니다. 이 과정에서 삭제 플래그가 표시된 세그먼트 병합을 수행합니다.
● translog
색인된 문서들은 루씬 commit까지 완료되어야 디스크에 안전하게 기록됩니다. 하지만 변경사항이 있을때마다 루씬 commit을 하기에는 루씬 commit은 너무 비용이 큰 작업입니다. 그렇다고 데이터를 모아서 commit을 한다면 장애 발생시 미처 commit하지 못한 데이터가 유실될 우려가 있습니다. 이를 위해 ES 샤드는 모든 작업마다 translog 라는 이름의 로그를 남깁니다. ES에 장애가 발생한 경우 장애 복구 단계에서 translog를 읽어 루씬 commit에 포함되지 못한 작업 내용을 복구합니다.
● 루씬 인덱스
여러 세그먼트가 모이면 하나의 루씬 인덱스가 됩니다. 엘라스틱서치 샤드는 이 루씬 인덱스 하나를 래핑한 단위입니다.
운영 전략
라우팅 활용
라우팅은 엘라스틱서치가 인덱스를 구성하는 샤드 중 몇 번 샤드를 대상으로 작업을 수행할지 지정하기 위해 사용하는 값입니다. 라우팅을 지정하지 않고 문서를 색인하는 경우 라우팅 기본값은 _id 값이 됩니다.
예를 들어, 로그인한 사용자가 작성한 댓글을 색인하는 인덱스를 만드는 경우입니다. 이런 경우 특정 아이디가 작성한 댓글을 모아서 조회하는 요청이 많이 들어올 것으로 예상된다면 로그인 아이디를 라우팅 값으로 지정하는 것이 좋습니다. 아이디가 동일한 문서끼리 같은 샤드에 위치시켜 검색 성능을 끌어올릴 수 있기 때문입니다.
물론 비즈니스 요건에 따라 라우팅 값을 지정할 수 없는 경우도 있지만 가능하다면 라우팅 값을 지정할 수 있는 형태로 서비스와 데이터 설계를 하는 편이 효율적인 방법입니다.
마스터 노드와 데이터 노드의 분리
어느정도 규모가 있는 서비스를 위해 클러스터를 운영한다면 마스터노드와 데이터 노드는 분리하는것이 좋습니다. 엘라스틱서치 운영 상황에서 문제가 생긴다면 데이터 노드가 죽을 확률이 높습니다. 이때 데이터 노드와 마스터 노드를 분리하지 않았다면 마스터 역할이 제대로 수행되지 않아 클러스터의 성능이 크게 떨어집니다.
ILM을 이용한 데이터 관리
인덱스 생명 주기 관리(Index Lyfecycle Manager, ILM)는 인덱스를 hot-warm-cold-frozen-delete 페이즈로 구분하여 조건을 만족하면 다음 페이즈로 전환시키고 이때 지정한 작업을 수행하게 할 수 있습니다.
구축 시나리오에 따른 구성
일 100GB의 데이터 분석과 장기간 보관 클러스터
하루에 100GB 이상의 큰 데이터를 저장하면서 보관 기간이 1년인 클러스터 시나리오를 생각해봅시다.
- 인덱스 이름 패턴은 일단위로 새로 만듭니다.
- 레플리카 샤드 개수는 1개
- 데이터 노드 한대에 할당할수 있는 SSD 용량은 2TB
위와 같은 경우에 인덱스의 총 개수는 365개, 클러스터에 저장되는 전체 예상 용량은 100GB * 365(일) * 2(레플리카 샤드) = 73TB 입니다.
단순히 생각해보면 73TB를 저장하기위해 데이터 노드가 37대는 되어야 할 것 같습니다. 장애상황 등을 고려하면 더 많은 노드가 필요해 보입니다. 하지만 보통 이렇게 오랜 기간 저장하는 데이터는 모든 데이터를 전부 자주 분석하지는 않습니다. 최근 1주일, 1개월 혹은 3개월등 기준으로 많이 조회하며 1년치 데이터를 조회하는 경우는 많지 않습니다. 이럴경우 데이터 노드를 hotdata / warmdata 형태로 구성할 수 있습니다. warmdata의 경우에는 고용량의 SATA 디스크를 사용할 수 있습니다. 다음과 같은 설정을 추가해 계산해봅시다.
- hotdata 노드 인덱스 보관 기간: 1개월
- warmdata 노드 인덱스 보관 기간: 11개월
- warmdata 노드 한 대에 할당할 수 있는 용량: SATA 10TB
데이터 노드의 개수를 계산해 봅시다. 엘라스틱서치는 기본적으로 노드의 디스크 사용률을 기준으로 샤드를 배치합니다. 이때 디스크 사용률이 85%가 넘으면 해당 노드에 샤드 할당을 지양합니다. 이를위해 최대 데이터 적재 용량을 80%로 잡고 계산해 봅시다.
hotdata 노드에 저장되는 전체 예상 용량은 100GB * 30(일) * 2(레플리카) = 6TB 입니다. 데이터 노드 한대에 2TB의 용량을 저장하고 적재 용량의 80%만 사용한다는 계산을 하면 총 4대의 데이터 노드가 필요합니다.

하지만 장애가 났을 경우를 고려해야합니다. 현재 레플리카 샤드가 1이기때문에 한대의 노드 장애에 대해서는 클러스터의 yellow 상태를 보장합니다. 만약 노드 장애가 오래 지속될 경우 다른 노드에서 충분히 받아줄 수 있는 용량을 확보해야 합니다. 따라서 장애 상황까지 고려하여 위 그림처럼 데이터 노드 5개로 클러스터를 구성해야 합니다.
- hotdata 노드 대수: 5대
- hotdata 노드 한 대의 볼륨 할당률: 6TB / 10TB * 100 = 60%
- hotdata 노드 한 대 장애 시 데이터 노드 한 대의 볼륨 할당률: 6TB / 8TB * 100 = 75%
- warmdata 노드 대수: 10대
- warmdata 노드 한 대의 볼륨 할당률: 67TB / 100TB * 100 = 67%
- warmdata 노드 한 대 장애 시 데이터 노드 한 대의 볼륨 할당률: 67TB / 90TB * 100 = 74%
구축 사례
Line Music
음악 스트리밍 서비스로 8,500만개 이상의 음악이 저장된다.

데이터 노드의 수를 정하는 기준은 Data Nodes <= Shards * (Replicas +1) 과 같다.

라인 뮤직에서 엘라스틱서치 인프라 구축을 위해 부하 테스트를 진행한 내용이다. 12개의 Node로 테스트를 진행할 경우 shard 6개, replica 1개가 가장 좋은 성능을 보였다. 곡 데이터는 총 73.8GB 이고 샤드 1개당 12.3GB로 분할하게 된다.
현재 실제 서비스에서는 데이터 노드 18개, 샤드 6개, 복제본 2개로 운영하고 있다고 한다.
출처
https://youtu.be/xP1QFpxhYi4?si=FkmQmaZN9Ua_QdHl
엘라스틱서치 바이블 (여동현 저) - 위키북스
기초부터 다지는 ElasticSearch 운영 노하우 (박상현, 강진우 공저) - 인사이트
'공부방' 카테고리의 다른 글
Proxy 와 Reverse Proxy (0) 2024.06.18 JPA 1대다 fetch join 주의사항 (0) 2024.04.02 파이프라인 프로토콜 (1) 2023.11.22 HTTPS 통신 과정 (0) 2023.11.15 OSI 7계층과 TCP/IP 4계층 (0) 2023.11.07